
Elasticsearch - Kibana for Data Collection
Elasticsearch as Opensource

Elasticsearch is opensource for the basic version, the basic version for cover most data capture needs – and Kibana is also free and yet very powerful for extracting and analysing data in real time.
We have developed our own API interface on top of Elasticsearch that allow use to collec, insert data as well as extract data across collected data – this is allowing us to integrate specific data groups into other systems.
ELK stack is delivering a set of free components that is very helpful in processing large amount of data – in our case are we mainly using Elasticsearch and Kibana – in combination with our own development.
We are operating Elasticsearch in one or many nodes with 32Gb ram.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
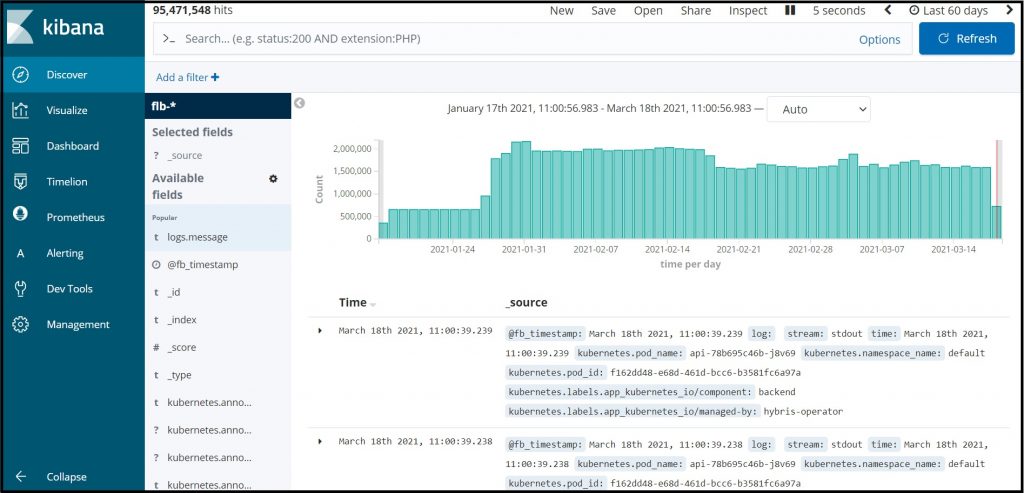
Collecting Data from Airplanes
We are as an example using Elasticsearch today to collect data from airplanes for L3Harris and Honeywell – these data are captured every 5 min and inserted into Elasticsearch using our added API interface.
After data have been added will we be able to analyse, filter and transfered certain data set across to a portal environment for data presentation, generation of alerts and reports.
Kibana allow the user to build real time views , extract wanted data set, be plotting on maps, build graphs and similar.
Companies using Elasticsearch
Around 2760 companies today use Elasticsearch including some tech-giants. Some of them are:

.
Elasticsearch and Netflix
Netflix relies on the ELK Stack across various use cases to monitor and analyze customer service operations and security logs. For example, Elasticsearch is the underlying engine behind their messaging system. In addition, the company chose Elasticsearch for its automatic sharding and replication, flexible schema, nice extension model, and ecosystem with many plugins. Netflix has steadily increased their use of Elasticsearch from a few isolated deployments to over a dozen clusters consisting of several hundred nodes.
Elasticsearch and Ebay
With countless business-critical text search and analytics use cases that utilize Elasticsearch as the backbone, eBay has created a custom ‘Elasticsearch-as-a-Service’ platform to allow easy Elasticsearch cluster provisioning on their internal OpenStack-based cloud platform.
Kibana
Accessing, searhing, presenting data in Elasticsearch can be done through Kibana that is extremly powerful when it come to handling data stored in Elasticsearch. Kibana allow the user to build real time data presentation on external web pages, directly into reports and especially search and filter functionality is making this tool a must have when running your big data into Elasticsearch.
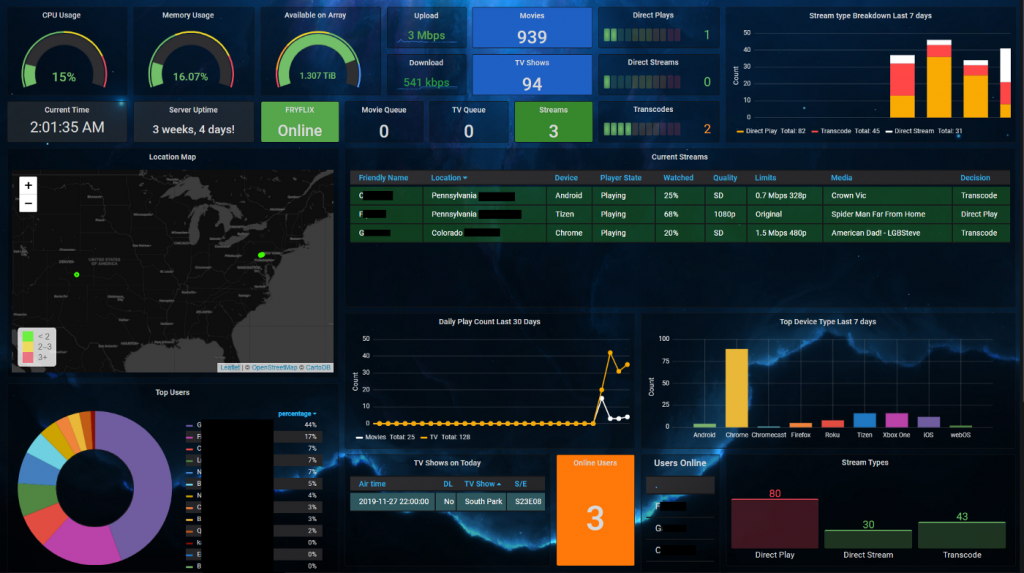
Grafana to present data
Data stored in Elasticsearch can also be displayed in a dashboard setup using Grafana – Grafana have the big advantage that it can combine data from Elasticsearch directly with data from a database.
Elasticsearch Fast and Compressed
Storing large amount of data into a database are miking it complicated to the fact that the database will be growing very fast and will be relative slow linked to the many inserts – database will also keep growing with little possibility to make it smaller again.
With Ekasticsearch is data inserted into a indexed taxt file model – that allow extrem fast search across basically any part of the data – it also have the very big advantage that it is using a limited amount of storage compared to a database setup..

Elasticsearch: Store, Search, and Analyse Large Volumes of Data Quickly and in Real-Time
The Elastic stack (ELK) is an impressive collection of open-source technologies, Elasticsearch, Logstash, and Kibana. Elasticsearch is a search and analytics engine. Kibana is more of a data visualization service that lets you visualize your data from Elasticsearch using various graphs and charts. We don’t use Logstach and Beats – but is using own developed tool to collect data.
What is Elasticsearch
Elasticsearch is a distributed, open-source search and analytics engine for all types of data, including textual, numerical, geospatial, structured and unstructured; known for its simple REST APIs, distributed nature, speed, and scalability. It allows you to store, search and analyse volumes of data quickly and in near real-time. Elasticsearch is mostly the main technology behind applications that have complex search features and requirements.
Elasticsearch provides REST endpoints for each service — to index the data, to fetch the data, to search through the data and to define our mapping as per the requirement.
Why use Elasticsearch
Imagine a business with a huge product and customer base. One of its customers wants to seek information about a product on their website. The website takes a long time to return a result, with some of the returned results irrelevant as well. This leads to poor user experience, and in turn, misses out on a potential customer.
The lag in search is linked to the website’s backend relational database performance. In a real scenario where an enterprise uses a relational database, all of its data will be scattered and distributed across multiple tables, with retrieving meaningful user information from multiple tables taking a long time. Relational databases perform slower when dealing with huge data that is being fetched through complex queries. Businesses today need technologies that can handle volumes data and provide search results in real-time. NoSQL databases are a better option here than relational databases for data storage and retrieval. Elasticsearch can be considered a NoSQL distributed database having no relations, no constraints, no joins and no transactional behaviour. Hence, Elasticsearch is easier to scale.
Elasticsearch takes in the query in a JSON format also known as Query Domain Specific Language (DSL). Real business queries are complex that require search using multiple fields, using different conditions and weights, etc. Elasticsearch can handle such complexities through a single query.
Use cases where Relational Databases is not useful:
- · Relevance based searching
- · Searching when the spelling of the search term is wrong
- · Full-text search
- · Synonym search
- · Phonetic search
- · Log analysis
Concepts around Elasticsearch
The backend of Elasticsearch involves the following components:
Index: An index is a collection of documents that have similar characteristics. For example, we can have an index for customer data and another one for a piece of product information. An index is identified by a unique name that refers to the index when performing indexing search, updates and delete operations. In a single cluster, we can define as many indexes as we want. Index = Database Schema in RDBMS.
Cluster: A cluster can be considered as a collection of one or more servers that store the entire data together and provide a federated view of the indexes and search capabilities across all servers. A cluster consists of one or more nodes that share the same cluster name. Each cluster has a single master node which can be replaced if the current master node fails.
Node: A node is a running instance of Elasticsearch which belongs to a cluster. Multiple nodes can be started on a single server. At a start-up, a node will use unicast to discover an existing cluster with the same cluster name and will try to join that cluster. We have found that each node need to have 32Gb RAM installed else will it start getting unstable when larger data set is captured.
Shards: Shards can be considered as a subset of documents of an index. An index can be divided into many shards.
Document: A document is a JSON file that is stored in Elasticsearch. It is like a row in a table in relational databases. Each document is stored in an index and has a type and an id. A document is a JSON object which contains zero or more fields, or key-value pairs.
ID: The ID identifies a document. The index/type/id of a document must be unique. If no ID is provided, it will be auto-generated.
Mapping: A mapping is like a schema definition in a relational database. Each index has a mapping, which defines datatypes for all the keys in that index.
Use-cases
Now that we understand the basics of Elasticsearch, it is paramount to know when to use Elasticsearch. Some of the impressive use cases of Elasticsearch are:
Text Search (searching for pure text): Applications that use lots of textual data can best make use of Elasticsearch wherein any specific search word/phrase could be quickly located through the huge volumes of data.
Auto-Complete: Based on the past searches, Elasticsearch auto-completes the partially typed words/search phrases.
Autosuggestion: As the user begins to start typing the search query, Elasticsearch suggests a few possible queries matching the one the user is typing.
JSON based storage: The documents are stored in Elasticsearch indexes in the JSON format.
Data Aggregation: This feature is useful to obtain analytics about the data that is indexed in the Elasticsearch. It allows the user to perform statistical calculations on the data stored.
To monitor and analyse application logs
Near Real-time Analytics
Elasticsearch is very much suitable for various use cases, with new features being added in every new version.